
Leveraging abstraction in a composable and headless commerce system is fundamental to good architectural design. By adequately implementing abstraction design patterns, merchants can avoid common pitfalls which unintentionally add expensive technical debt to distributed headless systems. Good abstraction practices will improve interoperability within the commerce stack. This improvement leads to increased agility on both the front and back end, improves headless shopping performance, reduces total cost of ownership (TCO), and lowers implementation costs associated with multi-head strategies.
This article will provide an overview of abstraction, including a look at the interoperability problems in the commerce stack today, review common abstraction anti-pattern oversights seen in poorly designed headless commerce stacks, and discuss the unintended consequences of these architectures.
- The danger of hardcoding
- The value of headless commerce abstraction
- Common mistakes and anti-patterns
- Summary of best practices
The danger of hardcoding
Hardcoding database connections and SQL statements directly into front end code repositories is a common mistake in poorly designed systems. In this abstraction anti-pattern, the engineer writes the connections and SQL statements to query a database directly into the interface codebase and pulls in the data needed for the front end components.
-1.jpeg?width=883&height=295&name=Nacelle_Imagens_Blog_Leverage_abstraction_1%20(1)-1.jpeg)
While fast and seemingly innocent, this approach is deeply flawed and adds significant technical debt. To stress-test the architecture, imagine a real-world scenario where the database changes for business reasons. It can change from a relational database of one variety to a relational database of another; a more extreme example would illustrate a change from a relational database to a NoSQL solution or vice versa.

Now the engineering team has a daunting issue; to move forward with the database change, each line of database connectors and SQL statements hardcoded into the front end must be ripped out and replaced. Essentially, the technical debt associated with improperly hardcoding and tightly coupling the back end and front end must be paid down before proceeding with the new business requirements. Herein lies the consequences of poorly designed architecture lacking abstraction; business changes move slowly, and velocity comes to a standstill.
The now out-of-vogue architecture pattern of Model-View-Controller (MVC) addressed this issue. Yesteryear's monolithic web frameworks like Ruby on Rails, PHP Larvel, Dot Net, and Python Django popularized the design for the web, but it was engineers working on Smalltalk-79 in the late 70s who initially conceived of the MVC abstraction model. The allure of MVC was easy to follow as it moved SQL code from the "View" (front end) and into the "Model" (back end). When the database changes in the MVC structure, only the Model code needs to be altered, as opposed to each individual "View" file.
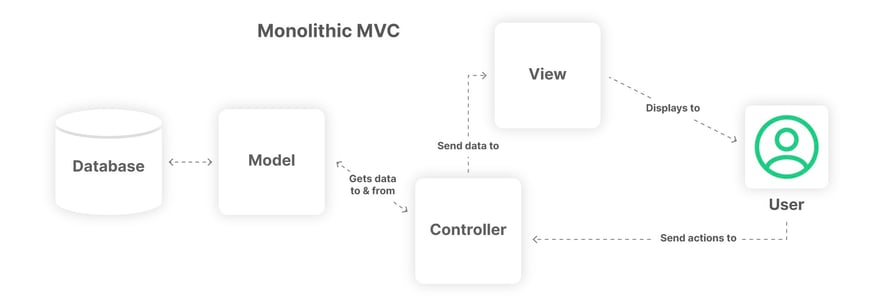
While the MVC framework was excellent in theory, it had numerous flaws, including the "fat" models, which sit outside this article's scope. One relevant issue in the MVC framework is the tight coupling between the "View" layer and the "Controller" which sat inside the monolithic architecture; this tight coupling prevented the adoption of new front end technology and is a source of pain for many legacy commerce systems built on MVC.
The value of headless abstraction
Headless solves the problem associated with tight coupling between the "View" layer and the back end components. Headless commerce is a separation between the front end and the back end, and this separation frees the front end of the traditional monolithic restrictions. This decoupled architecture makes adding front end technology upgrades to the stack significantly easier, thus lowering the cost of upgrading and leveraging new front end innovations.
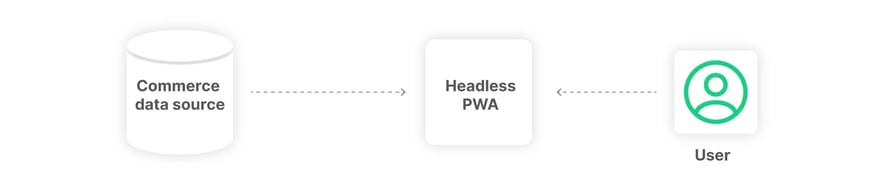
Less obvious, but arguably more important, the headless architecture lets the merchant leverage the full power of modern front end solutions. Modern advances in JavaScript allow client code to act, in and of itself, as a separate dedicated application. For example, headless commerce Progressive Web Applications (PWAs) sit entirely outside the back end system. By being separate, they can achieve astonishing performance that often improves page load speed by an order of magnitude. Further, well-designed PWAs leverage Single Page Applications (SPA) techniques resulting in a shopping experience where pages never have to be reloaded, even when switching from URL to URL. Such advances in the customer shopping experience would not be possible if the PWA were tightly coupled to the monolithic MVC "Controller" and "View" architecture.
Front-end innovation and agility
back end technology innovation, while robust, tends to move slower than front-end technology. The velocity of front-end innovation is painfully apparent when looking at recent innovations in the world of JavaScript. The industry has rapidly moved from scripting solutions that simply aided in manipulating the DOM, like jQuery, to a rapid progression of PWA solutions like the popular React. It is worth mentioning that React is not the only framework in the ecosystem; Angular, Vue, Ember, Svelte and Solid are also top contenders.
Solid and Svelte are particularly exciting because their performance is vastly superior to React. For example, Solid significantly reduces overhead and can achieve speeds twice as fast as React.
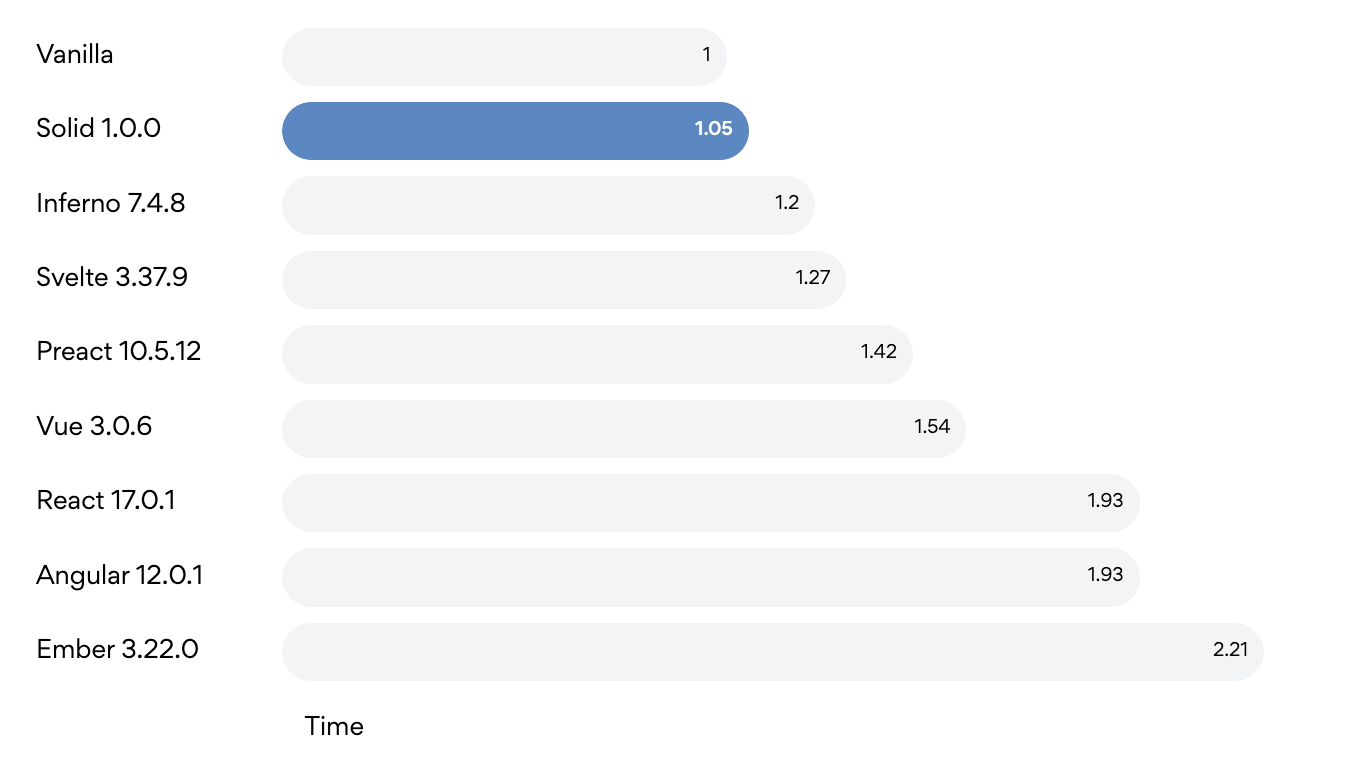
Of course, if a proposed architecture hardcodes its back end components to React front end components, the system will be at a significant disadvantage if it wants to leverage improvements like SolidJS as a competitive edge. Like the hard-coded database code previously mentioned, the technical debt associated with hardcoding React components to the back end will have to be paid down before leveraging the superior performance of a new front-end innovation.
Back-end changes
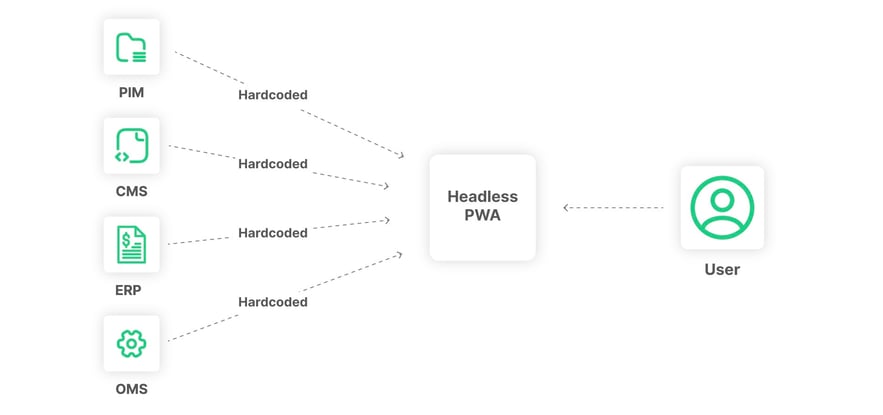
The aged-old problem of hardcoding takes many forms and surfaces in many ways when architecting an ideal composable and headless commerce system. For business end users, a headless CMS is often added to the merchant's stack; this headless CMS addition gives business users the ability to control a headless front end without developer intervention.
A flawed architectural solution that lacks foresight would simply call the CMS's SDK and APIs directly into the front end. The pattern leveraged here is analogous to the hardcoding database example above. If the CMS ever needs to change, a significant amount of technical debt must be paid down before progress occurs.
The same pattern must be avoided when incorporating commerce data. For example, product catalog data should not be coupled directly to a legacy monolithic solution or a dedicated Product Information Management (PIM) for the same reasons. Focusing first on interoperability and sound abstraction practices can limit technical debt, and the TCO of composable and headless solutions will be significantly improved.
The diagrams below compare a hardcoded composable commerce stack to one with better abstraction built-in via commerce data orchestration.
Headless performance and tribal knowledge
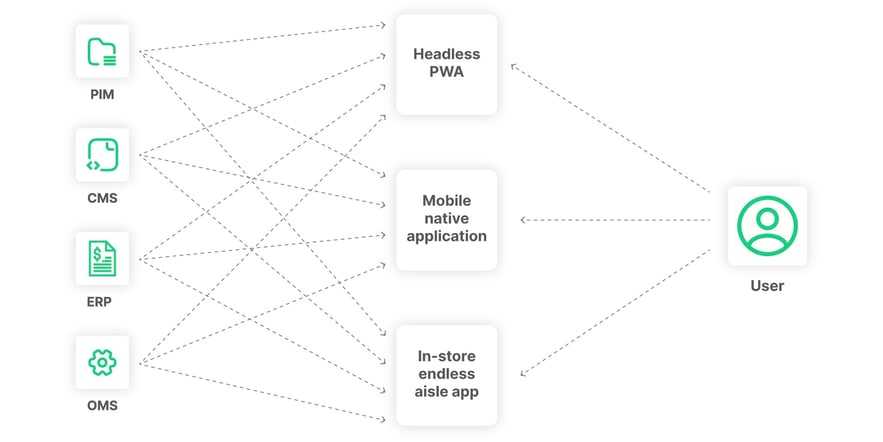
Architects must consider performance drawbacks when engaging in the anti-pattern of hardcoding back-end systems to headless front-end components. For example, crafting a Product Detail Page (PDP) requires API calls to multiple back-end systems. At a minimum, the code must query a Product Catalog and a Content Management system. More complex shopping experiences may require some additions, including live inventory availability API calls, a BOPIS API call, a shipping API call, a user API call, a reviews API call, and a price books API call to name a few. Often, these API calls must make multiple round trips to a server to fetch the required data.
Furthermore, the data cannot always be fetched in parallel since some API calls require parameters and inputs, which are the output of a different API. Therefore, complex querying for commerce shopping experiences is often executed sequentially, and the slow process dramatically impacts the performance of front-end code. The complexity expands when considering client-side try-catch best practices for API fetches. Once the data is received, the client code must transform the results and merge the objects from all sources. Unfortunately, all of this mistakenly occurs in the client-side codebase.
-1.jpeg?width=883&height=371&name=blog_abstraction_wires_2139x1456px%20(1)-1.jpeg)
The pain here is not simply performance but also organization. The code in this portion of the front-end system is unlikely to be well organized since the front-end code frameworks were not designed to solve complex data issues. Often this will result in technical debt and siloed-off tribal knowledge, which can only be refactored efficiently by the original authors of such code.
Multiple-headed strategies
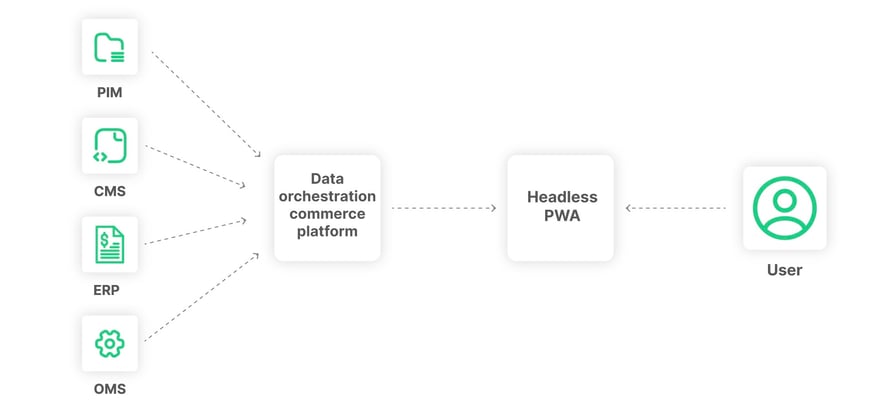
An explicit value of headless commerce lies in the ability to build shopping interfaces on multiple heads, known as multi-head. For example, a merchant may want to build a headless PWA to improve site speed, an endless aisle in-store app to improve the brick-and-mortar shopping experience, and a mobile native app to reach loyal customers through push notifications.
Unfortunately, a poorly designed headless architecture lacking abstraction will make the incremental addition of each new head costly. Consider the above PDP example where multiple APIs must be fetched, and the data has to be orchestrated and transformed inside the client code; all this code is written within the "head" of the Progressive Web App. However, it is not easy nor practical to share that code with another head. For example, the programming language and frameworks may not be consistent for different interfaces, and often, the work must be repeated from scratch. This inefficiency drives up the TCO for headless commerce when deploying a multi-headed strategy. The flaw speaks to an engineering best practice of Don't Repeat Yourself (DRY).
Alternatively, abstraction patterns can be implemented in a headless commerce design, thus avoiding a hardcoded solution. In this model, the data from the CMS and product catalog source coalesces and normalizes on the back end in a commerce platform that executes data orchestration. The client-side engineer then directly calls the API and SDKs for the commerce data orchestration platform instead of the best-of-breed data sources individually, thus adding a much-needed abstraction layer.
Common mistakes and anti-patterns
Headless Content Management Systems (CMS) are essential in composable and headless commerce architecture. Specifically, the CMS serves as the control center for the marketing business user; without this back-end component, an engineer would have to intervene and alter code to make even simple front-end changes. With a headless CMS, the business user can drag and drop to rearrange the front end at his or her will. Best-of-breed headless CMS vendors also account for previews, schedule future changes and robust content modeling solutions.
The superior headless CMS' in today's market delivers this functionality through API and avoids dependence on solutions that tightly couple front-end components.
Page builders and DXPs
Headless CMS solutions stand in contrast to page builders and Digital Experience Platforms (DXP), which frequently bind themselves directly to front-end components to execute their drag-and-drop and templatized functionality. While subtle, these systems are not purely headless due to their hardcoded nature. If not carefully implemented, technical debt can assume in the form of tightly coupled front-end components.
Examples of pitfalls associated with this architecture include but are not limited to vendor lock-in with hardcoded front-end components, inability to change front-end JavaScript frameworks rapidly to adopt new technology, and inability to cost-effectively launch multiple heads without repeating significant code logic and building wholly different content models for each head.
The CMS daisy chain anti-pattern
Another common pitfall associated with the headless CMS is the anti-pattern called the "Daisy Chain." Here, Product Catalog data mixes into the CMS back end, and the CMS API is used to query for both content and product data, thus making a "daisy chain" from the PIM to the CMS to the headless Front End.
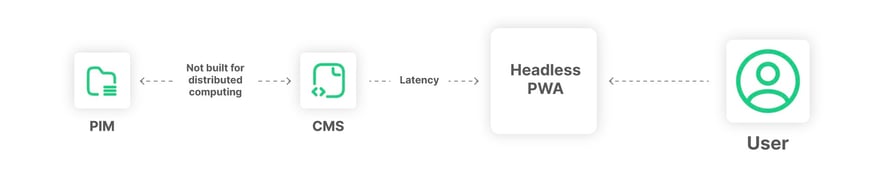
This flawed architecture is characteristic of poor design implementation and is addressed in the blog post on the daisy chain headless CMS anti-pattern. This particular distributed anti-pattern brings about issues of event messages and data flows. Therefore, it is advisable to avoid hardcoding the CMS directly into the front end and to keep a separation of concern between the commerce and content data in the distributed commerce architecture.
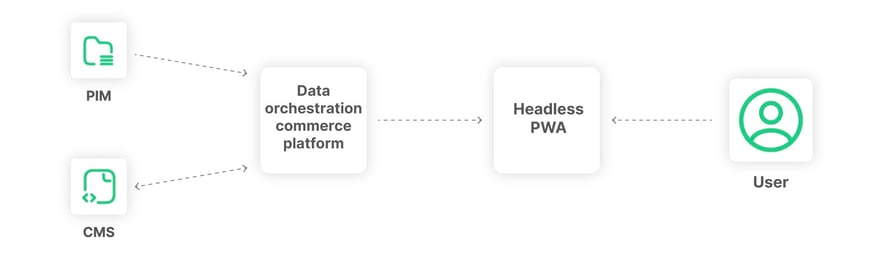
PIM hardcoding
Similar to the hard coding of a headless CMS, a Product Information Management (PIM) or similar product catalog solution should also be abstracted to avoid adding technical debt to the stack. These vendors may change due to business requirements, and even barring a change, the origins of product content and product data within a PIM may change. These alterations cause a cascading effect that could break front-end code if it is hardcoded directly. The usual consequences of skipping abstraction apply here, including increased difficulty with system-wide interoperability, vendor lock-in, inability to change stack components rapidly, and increased costs associated with multi-head rollouts.
Proprietary React frameworks
Several legacy commerce platforms have created proprietary front-end React frameworks to simplify headless deployments in their ecosystem. These frameworks let merchant developers use React to craft front-end shopping experiences and mistakenly believe that using React is the primary value of Headless Commerce. Examples of this architecture in the wild include Shopify's Hydrogen, Salesforce Commerce Cloud Composable Front End, and Adobe Magento's PWA Studio.
An example of Shopify Hydrogen hardcoding (taken from Hydrogen's documentation). here, the Hydrogen React components are tightly coupled to the router and data fetching on Shopify's back end.
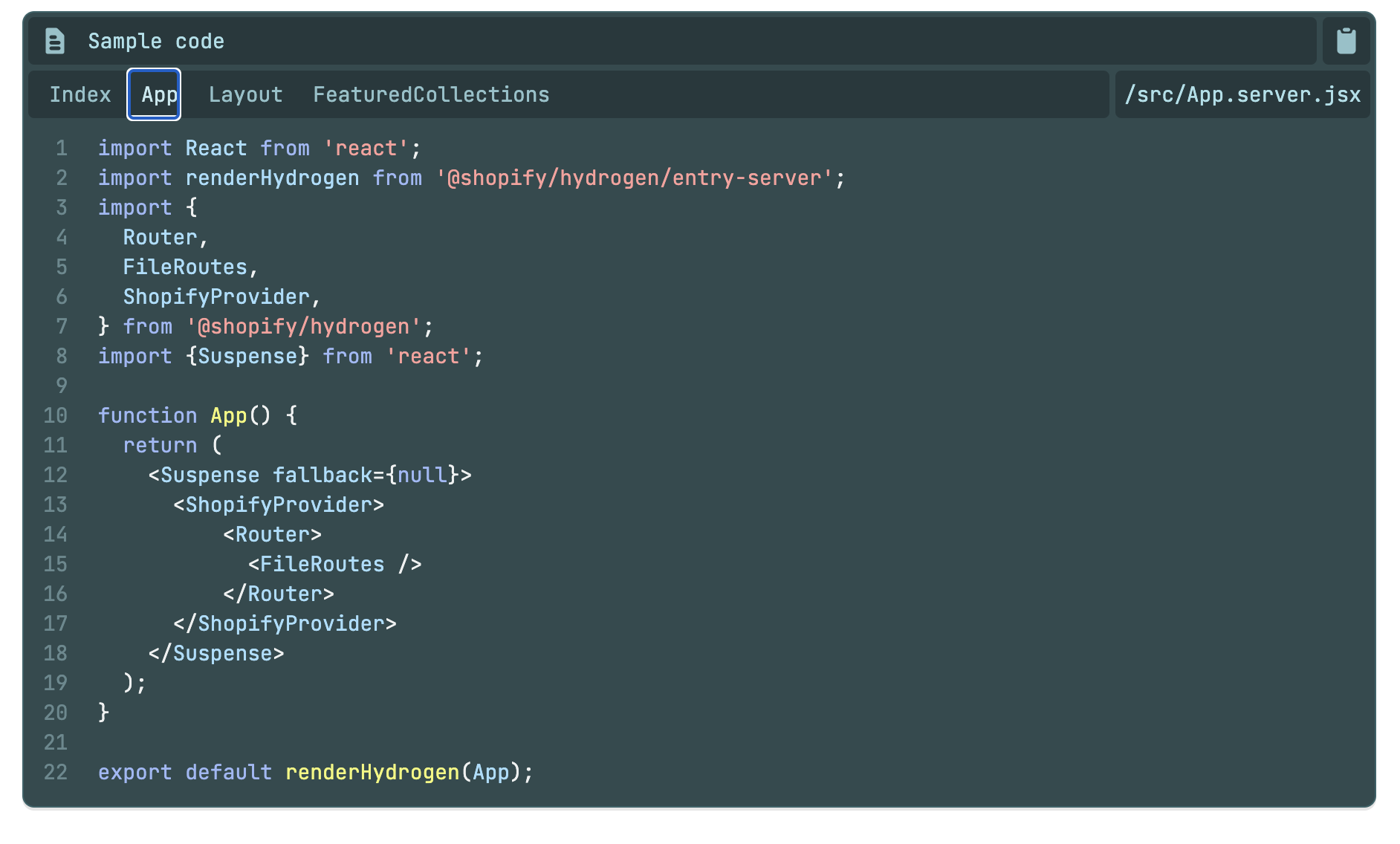
While admirable, these frameworks tightly couple the back-end platform to the front-end React components. This hard coding skips the step of abstraction and incurs technical debt. This structure is viewed as a defensive move to push vendor lock, thus keeping merchants on the legacy platform. Unfortunately, the technical debt burden of these frameworks, and their potent tight coupling, are not immediately noticeable. However, the pain associated with vendor lock-in, the inability to upgrade front-end technology (good luck using SolidJS!), and the added costs associated with repeat code when rolling out multi-headed solutions ensure that the unsuspecting merchant will regret their lack of foresight.
Summary of abstract value and best practices
Avoiding technical debt is imperative. In distributed systems, like those used in headless and composable commerce, abstraction must be leveraged to avoid architectural pitfalls, improve interoperability, and limit technical debt.
Several design patterns can help implement best practices when building headless commerce architecture. Client-side engineers should use care and consider classic object-oriented abstraction patterns when calling back-end data sources. Further, architects should strive to provide the cleanest data set to the front end to keep client code organized, deliver the best possible performance, avoid tribal knowledge build-up, and keep the total cost of ownership (TCO) low when rolling out a multi-headed commerce strategy.
Superior headless and composable commerce architecture solves abstraction and complexity before delivering data to the front end. The ideal solution abstracts commerce and content data into a canonical data model that is still performant yet flexible enough to account for merchant uniqueness. This system must be performant and should store, index, and cache the data for rapid API response times and request scalability. Given the regular changes to commerce and content data, this back-end abstraction should account for streaming events while also being able to handle regular batched updates.
Unfortunately, crafting such an architecture requires solving significant complexity and upfront capital investments, which is why it is often missing from today's composable and headless architecture. Given the distributed nature of such systems, issues related to eventual consistency, latency, parallel processing, resyncing, automatically fixing broken indexes, and scaling across a network all add intricacy to the problem.
A commerce platform built with data orchestration technology is an ideal solution for the distributed nature of composable and headless commerce architecture. Abstraction can be achieved quickly with commerce platforms like Nacelle without loading on technical debt. With this innovative technology, merchants can:
- Limit technical debt
- Increase system-wide interoperability
- Adapt with agility in the face of an ever-changing business environment
- Efficiently upgrade front-end and back-end systems
- Avoid tribal knowledge build-up and keep code clean
- Ensure fast performance
- Roll out compelling multi-head strategies in a cost-effective manner
- Lower the overall TCO of a headless and composable architecture